Real or Fake?
“Is this image real or fake?” I was confronted with that question many times recently, and too often, I was wrong. Over the last months, generative AI models have taken a massive step toward generating photo-realistic images. So much so that even professional photographers often cannot distinguish whether an image is real or not.
The last time I witnessed the power of today's AI models was at a talk by Julian van Dieken. Van Dieken got known for his image “The Girl with a Pearl,” which won the competition that sought a temporary replacement for Vermeer's painting of the same name. What made his work go viral was the way he created his image: Instead of crafting a photograph or painting, Van Dieken used an AI model to generated the winning image!


What most surprised me about his AI image (above on the left, https://shorturl.at/sFWY6), was how realistic it is. Especially the lighting and the fine details of the portrait first fooled me into believing that this was an actual photograph. In the 90 minutes of Van Dieken's talk, I did not only see more surprisingly realistic AI portraits, but also learned about the workflow of an AI artist. Van Dieken shared that he used a combination of Midjourney, an AI model, and Photoshop to create his version of “The Girl with a Pearl”.
After the talk, it was clear that I had to try out Midjourney myself. I was curious to see how easy it actually was to get realistic results, and at which point the technology would break down. Plus: As I mostly see images of people generated by Midjourney, I was excited to generate some nature shots.
From Text to Image in Seconds
The first thing I noticed when using Midjourney was how easy the whole process of generating an image is. After having subscribed to Midjourney and registered on their Discord server (a chat platform usually used by gamers), I could write prompts to the Midjourney Bot. I wrote a prompt in the form of "/imagine <keywords describing the desired image>", hit enter, and a few seconds later I had my first, AI-generated image.
After playing around with different keywords and styles, I quickly found out that it is so far hard to precisely influence the resulting images. This is especially the case when having a specific style or image in mind. One workaround I found was a technique one could call "describe and prompt." Instead of starting by writing a text-based prompt, you can drop an image in the Discord channel and let it describe by Midjourney’s "/describe" call. You then copy and paste the returned description into a "/imagine" prompt to generate a new image.
After running the “/imagine” prompt, you can decide between four images, which are more or less similar depending on how detailed your prompt is. You have the option to upscale each individual image (U1 – U4), create variations of each picture (V1 – V4), or rerun the same prompt (each run results in slightly different images). You can see an example of this procedure in the two screenshots below.

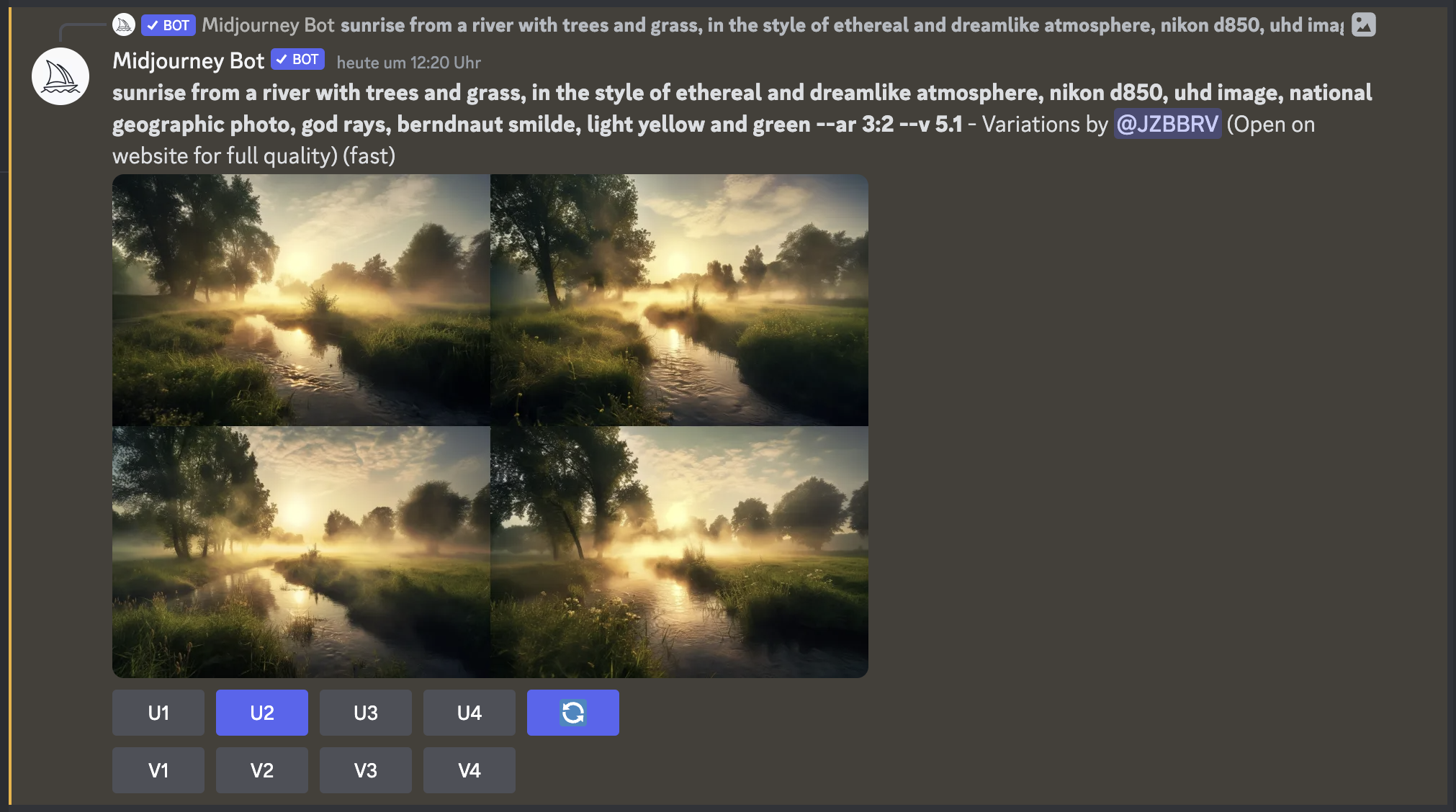

And what can I say: Especially color and composition-wise, the resulting images are outstanding! The title image of this post is straight out of Midjourney, except for some cropping and adjustments to the structure and clarity of the image.
Speaking of details: In my option, here is where I see the most room for improvement. Not only is the resolution you get out of Midjourney (1344 × 896 pixels) relatively low, but also the details often show weird textures. This can be seen best in the leaves of the trees and the grass in the foreground in the shot above.
At the same time, we must keep in mind that generative AI has just started producing usable image (as of May 2023). This point was also mentioned by Julian Van Dieken in his talk. He argued that the current state of AI models for image generation can be compared to when the first Nokia phones came out at the end of the 1990s, and that there is much room for improvement. I am curious to see what the generated images look like when the development of AI models has reached the stage of today's phones. Low image quality and odd-looking details won’t be an issue by then.
From Text to Painting with Image-Prompting
Next, I wanted Midjourney to get a bit more creative. Inspired by Van Dieken's success in getting his AI work hung next to other renowned paintings in the Dutch Mauritshuis Museum (!), I used Midjourney to reinterpret some of my images as impressionist paintings. To do so, I used the Midjourney option to include images in its “/imagine” prompt. For that, I uploaded pictures of mine into the channel, opened a new "/imagine" prompt, and copy and paste the link to an image into the prompt. I added a few keywords like "woodland, evening, kodak gold, impressionistic painting, monet --ar 3:2" and hit enter.


One result of this experiment can be seen above. The first picture shows the generated impressionistic painting, the second is the photograph of mine that I used in the image-prompt as a starting point. What excites me most about this result is the lake in the forest and the person standing in the middle of the frame. Not only are both of them great eye-catchers and drag me into the image, but they were both added by Midjourney. I did not (!) instruct it to do so. One could argue that Midjourney indeed showed some creativity here – what do you think?
One to Many
Inspired by the quality of the results I got from image-prompting, I used some of my street photography shots and tried to generate images of a similar style. For that, I again uploaded my photos to the channel and combined the link to the file with a few keywords in a prompt. The prompt for the first picture below, for instance, was the following: <link to uploaded image> abstract reflection, architecture --v 5.1 --seed 42 --ar 3:2. Below, you can see two generated images and the respective image used as a starting point (I took those by using a camera, no AI).




So, what’s my takeaway after spending three days and few hundred prompts with Midjourney (it seems like you have loads of time when being sick and got nowhere to go)? Overall, I can say that Midjourney is capable of producing excellent results. The lighting of the shots is most of the time on point, and the generated shadows look realistic. An impressive example of this is the third shot of the street series above (take a closer look at the shadows of the tree!). Color and composition-wise, I also didn't have any issues. All the shots shown in this post are directly out of Midjourney. I merely adjusted the exposure and decreased the structure and clarity to my taste in a few of the shots.
In contrast to the compositions, textures and fine details have the most room for improvement. Buildings still can come with weird shapes and details, and train tracks often show gaps right in the middle. Oh, and if you prefer people with one leg and three arms, you will love Midjourney!
What I wish most for is to have more control over the generation process. So far, getting a decent image is mostly trial and error. I add the link of an image to the prompt, include a few keywords, and hope for the best – that's how I created most of the results. I would have much preferred dreaming up a scene, describing it, and then getting what I had in mind. (A short example: Midjourney, please generate an image with two trees. What do I get? An Image of one tree. Urgh!)
At the same time, I am convinced that the described shortcomings are only a temporary thing. When looking at Midjourney and similar models in a few months (or weeks?), named issues won’t be a problem anymore. And who knows, as thought-to-text seems a thing now, we then even might be able to visualize a scene and get an image without having to touch a keyboard at all. Crazy times.
Welcome to Distopia! Creating scenes like they were taken from Blade Runner 2049 with Midjourney. (Prompt: /imagine brutalism, dystopia, traffic, air pollution, in the style of Blader Runner, dark sky, science fiction, blue hour, 8k, Kodak Ultramax 400 --v 5.1 --seed 42 --ar 3:2)